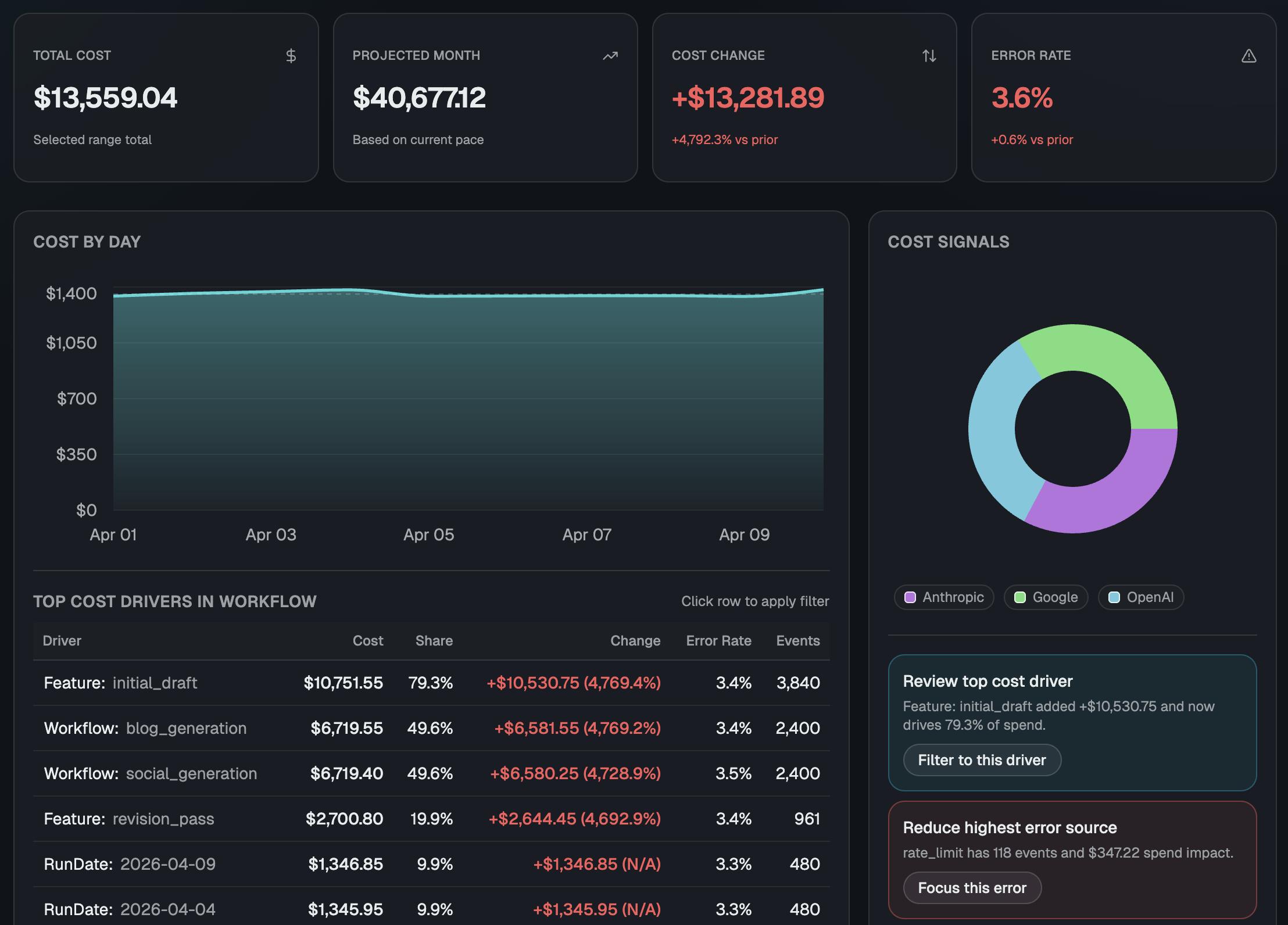
zsh — typescript
import {
createAiTokenTrackerInterceptionScope,
withAiTokenTrackerInterceptionScope,
} from "@ai-token-tracker/sdk";
// Create scope-level filter context for this workflow/request boundary.
const scope = createAiTokenTrackerInterceptionScope({
// Workflow tag groups related calls in dashboard analytics.
Workflow: "social_post_generation",
});
// Add more business tags used for filtering and grouping.
scope.addCustomFilters({
// Job tag links usage/cost back to one business job.
JobId: "job-42",
// Customer tag enables tenant/customer-level cost analysis.
CustomerId: "cust-19",
});
// Run call inside scope helper so interception reads active filters.
await withAiTokenTrackerInterceptionScope(scope, async () => {
// Execute actual provider HTTP call here.
await fetch("https://api.openai.com/v1/responses", {
method: "POST",
// Set HTTP headers required by provider/auth flow.
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
"content-type": "application/json",
},
// Serialize request payload sent to provider.
body: JSON.stringify({
model: "gpt-4.1-mini",
input: "hello",
}),
});
});
$ // interception scope active
import {
createAiTokenTrackerInterceptionScope,
withAiTokenTrackerInterceptionScope,
} from "@ai-token-tracker/sdk";
// Create scope-level filter context for this workflow/request boundary.
const scope = createAiTokenTrackerInterceptionScope({
// Workflow tag groups related calls in dashboard analytics.
Workflow: "social_post_generation",
});
// Add more business tags used for filtering and grouping.
scope.addCustomFilters({
// Job tag links usage/cost back to one business job.
JobId: "job-42",
// Customer tag enables tenant/customer-level cost analysis.
CustomerId: "cust-19",
});
// Run call inside scope helper so interception reads active filters.
await withAiTokenTrackerInterceptionScope(scope, async () => {
// Execute actual provider HTTP call here.
await fetch("https://api.openai.com/v1/responses", {
method: "POST",
// Set HTTP headers required by provider/auth flow.
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
"content-type": "application/json",
},
// Serialize request payload sent to provider.
body: JSON.stringify({
model: "gpt-4.1-mini",
input: "hello",
}),
});
});
$ // interception scope active
import {
createAiTokenTrackerInterceptionScope,
withAiTokenTrackerInterceptionScope,
} from "@ai-token-tracker/sdk";
// Create scope-level filter context for this workflow/request boundary.
const scope = createAiTokenTrackerInterceptionScope({
// Workflow tag groups related calls in dashboard analytics.
Workflow: "social_post_generation",
});
// Add more business tags used for filtering and grouping.
scope.addCustomFilters({
// Job tag links usage/cost back to one business job.
JobId: "job-42",
// Customer tag enables tenant/customer-level cost analysis.
CustomerId: "cust-19",
});
// Run call inside scope helper so interception reads active filters.
await withAiTokenTrackerInterceptionScope(scope, async () => {
// Execute actual provider HTTP call here.
await fetch("https://api.openai.com/v1/responses", {
method: "POST",
// Set HTTP headers required by provider/auth flow.
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
"content-type": "application/json",
},
// Serialize request payload sent to provider.
body: JSON.stringify({
model: "gpt-4.1-mini",
input: "hello",
}),
});
});
$ // interception scope active